Python3将爬取的数据存储到Excel
我们学习 Python3 爬虫的目的是为了获取数据,存储到本地然后进行下一步的作业,今天小雨就教大家 python3 如何将爬取的数据插入到 Excel 我们直接来讲如何写入 Excel 文件: 基本流程就是:新建工作簿--新建工作...

Python3学习群重要通知,群友必看!
很多人进群后不及时提交作业,不珍惜这个学习的机会,陌小雨就设置一些门槛,特此申明如下(2018-3-14): 很多初学 python 的朋友,苦于找不到一群志同道合的朋友,陌小雨给大家提供了一个平台,一个纯粹学习 py...

Python3作业二:输出豆瓣top250电影名,一行一个
在python3 爬虫利器 Xpath:用 Xpath 提取文本这篇文章中,我们学会了用 Xpath 来提取网页中的文本,输出的格式是这样的 那么如何一行一个的输出呢? 这需要我们复习下小白教程中的列表和循环的章节,作为本次的...
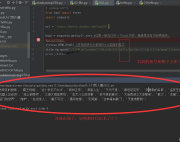
python3爬虫利器Xpath:用Xpath提取文本
本篇文章需要前 3 篇文章的知识: Python3读取网页源代码我们用安装lxml库的方法来安装requests库,就可以用requests来读取网站的源代码了 [gzh2v keyword="9999" key="dedewp"] 还是以豆瓣电影top250为...
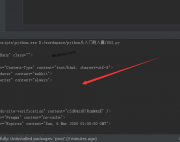
Python3读取网页源代码
我们用安装lxml库的方法来安装 requests 库,就可以用 requests 来读取网站的源代码了 请输入验证码查看内容 验证码: 微...
Pycharm安装第三方库lxml
还记得我们前面添加 python 解释器的时候么,默认的只有 3 个 请输入验证码查看内容 验证码: 微信扫码,回复关键字“9999”...

python3爬虫利器Xpath:认识Xpath
首先,我们来认识什么是 Xpath 请输入验证码查看内容 验证码: 微信扫码,回复关键字“9999”获取验证码即可查看 ...
Python3作业一:输出QQ号和昵称
1、新建 01hello.py 文件 请输入验证码查看内容 验证码: 微信扫码,回复关键字“9999”获取验证码即可查看 ...
Pycharm新建项目
1、运行 Pycharm 后,我们就可以新建一个项目 请输入验证码查看内容 验证码: 微信扫码,回复关键字“9999”获取验证码即可...